簡単なシミュレーションを試して、それを理解してみませんか?これがRでコード化されたものです:
library(ROCR)#このパッケージをROC &AUCに使用します
set.seed(8365)#これにより、例が正確に再現可能になります
x = c(runif(50、min = 0、max = 4)、#xデータには4から6のギャップがあります
runif(50、最小= 6、最大= 10))
y = ifelse(x<5、0、1)#低い値はすべて0です。より高い値1
m = glm(y〜x、family = binomial)
要約(m)
#..。
#逸脱度残差:
#最小1Q中央値3Q最大
#-2.961e-05 -2.110e-08 0.000e + 00 2.110e-08 2.674e-05#残差すべて〜0
#
#係数:
#標準を推定します。エラーz値Pr(> | z |)
#(切片)-98.42 75721.51 -0.001 0.999#巨大な係数& SE
#x 19.42 14525.40 0.001 0.999
#..。
#
#ヌル逸脱度:99自由度で1.3863e + 02
#残差逸脱度:98自由度で2.6504e-09#残差逸脱度〜0
#AIC:4
#
#フィッシャースコアリングの反復回数:25#非常に多くの反復
pred = Forecast(predict(m、type = "response")、y)#これらはROCを作成します
perf = performance(pred、 "tpr"、 "fpr")
performance(pred、 "auc")@ y.values [[1]]#これはAUCです
#[1] 1
窓(幅= 7、高さ= 4)
layout(matrix(1:2、nrow = 1))
plot(x、y、main = "データと適合モデル")
xs = seq(0,10、by = .1)
lines(xs、predict(m、data.frame(x = xs)、 "response")、col = "red")
plot(perf、main = "ROCcurve")
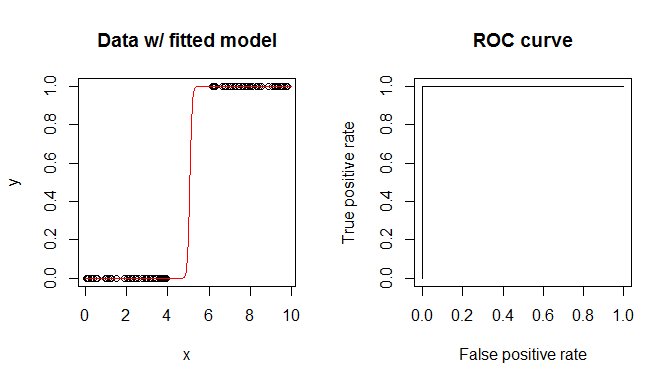
出力と図に表示されているのは、AUCが$ 1 $であるということです。 AUCは、ROC曲線の下の領域です。 ROC曲線は、それを超えるとクラス$ 1 $を予測するしきい値を変更することによって計算されます。次に、各ポイントで、実際のクラスに対して予測されたクラスを調べ、真陽性率と偽陽性率を決定します。 ROC曲線は、これら2つのレートのプロットにすぎません。ただし、使用するしきい値に関係なく、完全な精度が得られることに注意してください。したがって、ROCの「曲線」は必然的に単位正方形の左側と上面になり、その下の面積は$ 100 \%$になります。
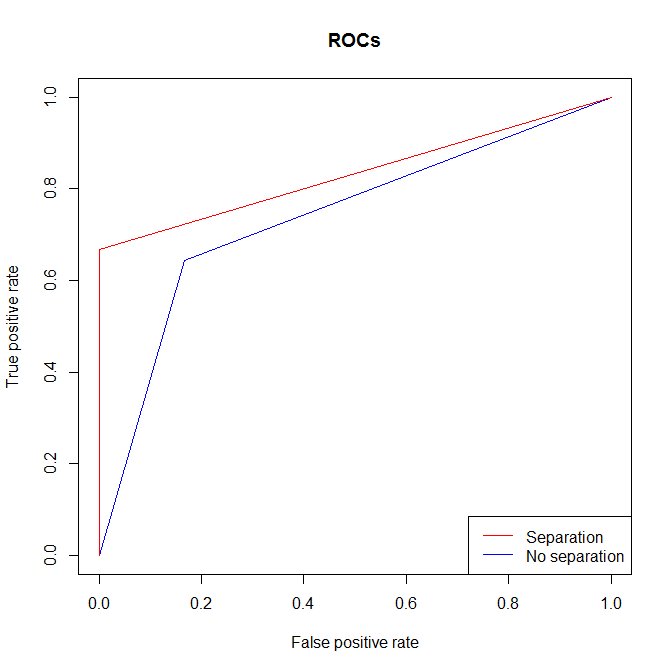
@Clif ABは、$ AUC = 1 $がなくても分離できるという良い点を示しています。これがその場合の実例です。それでも、分離がない場合とほぼ同じ場合よりも、分離がある場合の方がAUCが高くなることがわかります。理由は基本的に同じです。しきい値をどこに設定しても、分離可能なデータからの真陽性率と偽陽性率は、そうでない場合よりも優れています。
x = rep(0:1、each = 10)
y1 = c(0,0,0,0,0,1,1,1,1,1、
0,1,1,1,1,1,1,1,1,1)#x = 1の場合は0。分離なし
y2 = c(0,0,0,0,0,1,1,1,1,1、
1,1,1,1,1,1,1,1,1,1)#x = 1の場合は0なし。分離
m1 = glm(y1〜x、family = binomial)
m2 = glm(y2〜x、family = binomial)
summary(m1)#出力を省略
summary(m2)#出力を省略
pred1 =予測(predict(m1、type = "response")、y1)
perf1 = performance(pred1、 "tpr"、 "fpr")
performance(pred1、 "auc")@ y.values [[1]]#これはAUCです
#[1] 0.7380952
pred2 =予測(predict(m2、type = "response")、y2)
perf2 = performance(pred2、 "tpr"、 "fpr")
performance(pred2、 "auc")@ y.values [[1]]#これはAUCです
#[1] 0.8333333
ウィンドウズ()
plot(perf1、col = "blue"、main = "ROCs")
plot(perf2、col = "red"、add = T)
legend( "bottomright"、legend = c( "Separation"、 "分離なし")、
lty = 1、col = c( "red"、 "blue"))